宮商定時制計算部
計算部日記190301
夏以来の更新になります。
今回は、計算部の昨年一年間の活動のうち、まだこのサイトに書いていないものを簡単に報告しておきたいと思います。
Linux用音声読み上げプログラム(2018年上半期の冬・C++)
テスト勉強などの音声学習のために制作しました。
ただし、読み上げる音声ファイルを生成する部分は自作ではなく、Open JTalkを使わせてもらいました。
具体的には、
テキストを1バイトずつ読み込みながら文字数をカウントしていく。
あらかじめ設定した上限文字数に達する前に改行が出てきたら、そこで切る。
上限文字数に達しても改行が出てこない場合は、その終端から最も近い区切り文字(受け約物など)を探して、そこで切る。区切り文字は、「。」→「!」→「?」→「」」→「)」→「』」→「》」→「;」→「:」→「、」→「 」→……という具合に、まず「文の切れ目」を探し、それがなければ「句の切れ目」を探す。
(以下繰り返し)
という処理としました。
UTF-8の文字をカウントするのは、それほど難しい処理ではありません。
int fc_ccount(unsigned char c) {
if (c <= 0x20 || c == 0x7f) { //制御コード等(ノーカウント)
return 0;
} else if (c <= 0x7e) { //1バイト文字(カウント)
return 1;
} else if (c <= 0xbf) { //2~6バイト文字2バイト目以降(ノーカウント)
return 0;
} else if (c <= 0xfd) { //2~6バイト文字先頭(カウント)
return 1;
} else { //使われていない範囲(ノーカウント)
return 0;
}
}
こうして区切ったテキストをOpen JTalkに次々に読み込ませて、切り分けたテキストの数だけwavファイルを作ります。
「僕もね、僕も考えたことがあるんだ」その子は言った。「僕らがしなきゃいけないことだよ。二人の血を少し交換するんだ、君と僕で。そうすれば、僕らは永遠に結ばれるだろう」
このサンプル・テキストは748字あるため、一度にOpen JTalkに読ませることはできませんが、このプログラムを使えば、テキストの切り分けからmp3作成まで自動でやってくれます。
↑「エラー」「無効なソース」などが表示される場合は、
こちら
をクリックしてみてください。
誤読もありますが、まあこの程度読み上げてくれれば十分でしょう。
イーディスの太った頬に数行の涙が伝った。なぜだろう、とアーマはいぶかしんだ。なぜ神は、人々の一部をこんなふうに不器量で不愉快に、ほかの一部をミランダのように美しく親切にお創りになったのだろう。愛しのミランダは、冷たい手で子供の熱い額を撫でようと屈んでいる。時々、パパの最高級のフランス・シャンパンや、春の午後の鳩のもの憂げな鳴き声によって生じてくるような、理屈を超えた優しい愛が、彼女の心を溢れんばかりに満たした。イーディスのたわごとを処理するミランダを、無情な微笑で待っているマリオンをも含む愛。涙が込み上げてきたが、悲しいわけではない。泣きたいなどとは全く思わない。ただ愛したいだけ。彼女は、自分がその影に横になっていた岩の上に立ち上がり、巻き毛を振り広げながら踊り始めた。いや、むしろ、温かく滑らかな石の上を滑り始めた、とでも言うべきかもしれない。イーディスを除く全員が、ストッキングと靴を脱いでいた。彼女は裸足で踊っていた。巻き毛とリボンを振り乱している、明るくうつろな目をしたバレリーナのように、小さなピンクの爪先が表面をほとんどかすることなく。彼女は、六歳のときに祖母に連れて行かれたコヴェント・ガーデン劇場にいた。舞台袖のファンにキスを投げ、一等席にブーケから抜いた花を放り込む。最後に彼女は、ユーカリの木の真ん中辺りのロイヤル・ボックスに向かって深々とお辞儀をした。イーディスは巨礫にもたれて、次の小さな坂に進もうとしているミランダとマリオンを指さした。「アーマ、ちょっと見て。あの人たち、靴も履かないで、いったいどこに行こうとしているのかしら?」困ったことに、アーマは笑っているだけだった。イーディスは不機嫌に言った。「気が狂ったに違いないわ」そのような放埒な愚かさは常に、幼いころにウールのルームソックスとガロッシュを与えられるような、イーディスや彼女の同類たちの理解を超えるものなのだ。精神的援助を求めてアーマの方を向くと、彼女もまた靴とストッキングを拾って腰に吊り下げているのが見え、イーディスはぞっとした。
このサンプル・テキストは866字あるため、やはり一度にOpen JTalkに読ませることはできません。。 」の句点と、その句点の直後から数えて297字目の「ロイヤル・ボックスに向かって深々とお辞儀をした。 」の句点の、二箇所で切り分けられることになります(もし句点が一つもなければ、次は「!」を、それもなければ「?」を……と探していき、万が一区切れる記号が一つも見つからなければ、やむを得ずエラーメッセージを表示して、ユーザーに適当に区切り記号を挿入するよう促します)。
↑「エラー」「無効なソース」などが表示される場合は、
こちら
をクリックしてみてください。
う~ん、前のテキストよりも誤読が増えていますね……。
……実は、顧問は普段Windowsを使っているので、このプログラムは利用していません。
国語の教員にはWordよりも一太郎を使う人が多く、顧問もその一人です。
リスト構造の練習(2018年夏・C)
ここに、前の日記に書いた「リスト構造――可変にできるものは全部可変にしてみよう!」が入ります。
ドローイング練習ソフト(2018年秋・C++・Qt)
そこそこ有名な絵の練習ソフトに『30秒ドローイング』というのがあります。
以前にも書いたように、Qtには、初心者がゼロから応用まで無理なく学べる日本語の参考書がありません。
このあたりになってくると、部の活動の主導権は完全に部員が握っていて、顧問は付いていくだけという状態になっています。
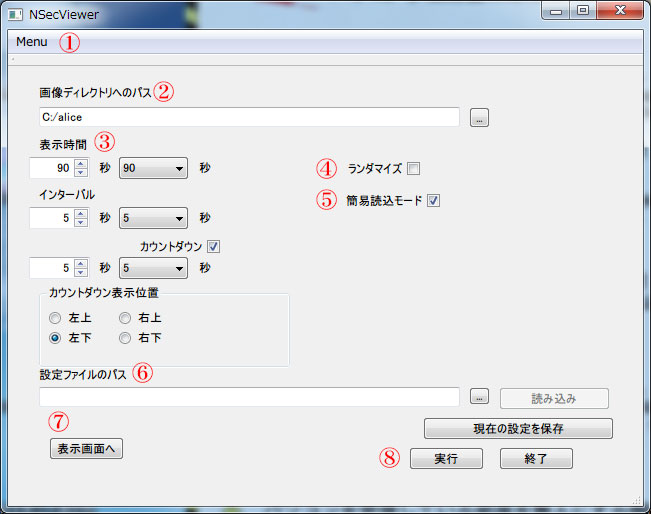
Windowsでビルド&実行した設定画面です(Qtらしく、Linuxでも同じコードでビルド&実行できます)。
①ここでは見えませんが、「Menu」をクリックすると「設定画面に戻る」「一時停止」が現れます。
②表示したい画像フォルダを指定します。なお、二度目以降の起動では、前回終了時に指定していたフォルダのパスが自動的に入ります。
③表示時間・インターバル・カウントダウンの各秒数を指定します。秒数は、左のスピンボックスに直接値を入力してもいいし、右のコンボボックスから選んでもかまいません。コンボボックスで選んだ秒数はスピンボックスにも入りますし、逆にスピンボックスに入れた秒数がコンボボックスの選択肢にある場合は、コンボボックスの値も連動して変化します(コンボボックスの選択肢にない場合はコンボボックスは空白)。
④「ランダマイズ」にチェックを入れると、フォルダ内の画像をランダムな順番で表示します。ランダムにした場合でも、同じ画像が複数回表示されることはありません。
⑤「簡易読込モード」にチェックを入れると、拡張子によって画像ファイルかどうかを判別し、画像ファイルだけを表示します。これにチェックを入れない場合は、一旦すべてのファイルを読み込み、内部構造が画像ファイルであるもののみを表示します。Windowsのように拡張子必須のOSの場合はチェックを入れ、拡張子を必ずしも必要としないOSの場合はチェックを外すようにします。ただし、後者の場合は、すべてのファイルの内部構造をチェックしますので、ファイルの数が多い場合はスタートするまでにかなり時間がかかります。
⑥設定をiniファイルに記録しておくことができます。iniファイルは、それぞれに違う名前を付けておけばいくつでも保存できます。画像フォルダごとに違う設定にしてiniファイルとして保存しておけば、それぞれのフォルダでいちいち設定をし直さなくても、そのフォルダ用のiniファイルを読み込むだけで設定を再現できます。
⑦表示画面に移るためのボタンです。
⑧実行ボタンと終了ボタンです。
表示画面です。
サンプル画像はルイス・キャロル『不思議の国のアリス』の挿絵より(ジョン・テニエル画、パブリックドメイン)
(1)次の画像が先取り表示され、画像の中央にインターバル用カウントダウン秒数が現れます。
(2)インターバル用カウントダウンが消えると、画像表示になります。これを設定秒数以内で描き写すことで、絵を素早く正確に描く練習をします。
(3)「カウントダウン」にチェックを入れた場合、あと何秒で次の画面に移るかのカウントダウンが表示されます。画面四隅のどこに表示するかも選べます。
(4)以下、フォルダ内の画像ファイルをすべて表示するまで(1)~(3)を繰り返します。一時停止もできます。
設定画面と表示画面は同じウインドウ上に表示されますが、これはQtのStacked Widgetで実現しています。
さて、このソフト、実はこれを書いている2019年2月現在、まだ完成していません。
それは、インターバルで次の画像を先取りしているとき(上の(1)のとき)、画像を薄く表示して、カウントダウン数字の方を目立たせる処理です。
そのほかにも、何となくうまくいってはいるけれど、自信が持てないでいる部分もあります。
レイアウト機能を使用すると、上図のようにウィジェット(ここではラベル)を重ねて配置しておいたとしても、強制的に分離されて並べ直されてしまいます。
void MainWindow::resizeEvent(QResizeEvent *event)
{
int dif_w = event->size().width() - v_wSize->width();
int dif_h = event->size().height() - v_wSize->height();
//カウント表示用ラベル群の動的サイズ変更。こちらを先にする必要あり?
ui->lblIntervalNumber->setGeometry(event->size().width() / 2
- v_intvLblSize->width() / 2 - 10,
event->size().height() / 2
- v_intvLblSize->height() + 40,
v_intvLblSize->width(),
v_intvLblSize->height());
ui->lblUpperCountDown->setGeometry(v_cdUpLblSize->x(),
v_cdUpLblSize->y(),
v_cdUpLblSize->width() + dif_w,
v_cdUpLblSize->height());
ui->lblLowerCountDown->setGeometry(v_cdLoLblSize->x(),
v_cdLoLblSize->y() + dif_h,
v_cdLoLblSize->width() + dif_w,
v_cdLoLblSize->height());
//画像表示用ラベルの動的サイズ変更。これは必ず後?
ui->lblImage->setGeometry(v_imgLblSize->x(),
v_imgLblSize->y(),
v_imgLblSize->width() + dif_w,
v_imgLblSize->height() + dif_h);
if (!v_pix->isNull() && !ui->lblImage->pixmap()->isNull()) {
ui->lblImage->setPixmap(v_pix->scaled(ui->lblImage->size(),
Qt::KeepAspectRatio));
}
}
これでまあ期待どおりの動作はしてくれたのですけれども、この部分、コードの記載順をカウント表示用ラベル→画像用ラベルにしておかないと、なぜか動かなくなってしまうことがあるのです。
そういう次第で、まだすっきりしない部分が残ってはいるけれども、とりあえず自分たちで使う分には問題なく動作するようなので、それなりの達成感を味わうことはできました。
……これは顧問の感想ですが、繰り返し使ってみると、やはりGUIアプリはCUIプログラムよりも使いやすいと感じます。
ただし、部員A君はちゃんと絵の練習という本来の用途で使用しているのに対し、顧問はもっぱらスライドショーとしての用途でしか使っていませんw。
珠算読み上げ算プログラム(2018年下半期の冬・C++)
顧問は大昔、日商珠算検定の1級に合格しています(70年代半ばのことで、まだ検定種目に「伝票算」があった時代です)。
読み上げ算にルールのようなものがあるのかどうかは、実は顧問も知りません。
読み上げ算の多くは10口のようだが、5口や15口など、問題の長さを自由に設定できるようにする。
すべて加算にするか、減算を入れるかを選べるようにする。
減算が入る場合、減算の数を調整できるようにする(減算の数は3~5割くらいが普通らしい)。
減算が入る場合、最終解答も計算途中もマイナスにならないよう調整できるようにする。
初心者は1~2桁程度の計算で十分だが、上級者向きに極めて大きな桁を扱う問題も生成できるようにする。
数値の桁数が偏らないようにする。……例えば5~10桁の読み上げ算の場合、最小桁数の5桁の数値と最大桁数の10桁の数値が必ず一度は入るようにし、さらにすべての桁数の登場回数が平均的に散らばるようにする。
減算が連続する箇所で、「引いては」を最初に一度しか言ってくれない場合と、二番目以降も「なお引いては」といちいち言ってくれる場合とがある。どちらのスタイルも選べるようにしたい。
数値の途中に「0」がある場合、例えば「¥2004」の場合、普通に「にせんよ円なり」と読む場合と、「にせんれいれいよ円なり」「にせんぜろぜろよ円なり」「にせんとびとびよ円なり」などと「0」を読んでくれる場合とがある。音声読み上げプログラムに「2004円なり」というテキストを読ませると、当然前者になる。これを後者のように、「0」があることを知らせる読み方で読ませるプログラムを書くことも、できなくはなさそうである。しかし、これを実現させるとなるとかなり煩雑なプログラムになることが予想されたので、今回は見送ることにした。
読み上げのスピードを調整できるようにする。
プログラムを設計する上で、たぶんいちばん最初に考えなければいけないのは、5.の「上級者向きに極めて大きな桁を扱う」部分であろうと予測しました。
これで読み上げ算を一つ作ってみると、次のようになります。
330,651,252,866,193,012,636,801,847,614
3,756,342,807,477,770,038,614,517,249,030,717
24,872,554,759,550,866,660,350,613,546,148,297
696,765,317,384,796,841,603,684,886,926,042,563
-84,565,804,493,475,724,824,040,899
22,250,809,556,700,412,851,782,163,777
859,354,326,426,885
3,615,603,900,843,187,767,676,150,774,459,507,793
20,698,852,819,225,993,678,740,183,717,684,011,318,533,053,118,265
-532,965,604,592,347,487
-536,219,707,854,544,340,847,771,526,196,332,945,142,877
-372,544,117,735,998,526,831,821,880,592,485,031,747,238,371
-2,654,632,680,594,646,003,052,419,471,524,742,041,195
9,291,390,814,141,688,322,850,279,783
-8,463,698,715,167,664
-------------------------------------------------------------------
20,698,479,736,238,258,143,552,268,945,657,453,034,573,428,587,201
こんなにも大きな桁数の読み上げ算は(これが見取り算だとしても)、さすがに全国大会でも出てこないでしょうが、int型では不可能な桁数の計算が可能であるということを示すために、あえてこうしてみました。
15 桁の数字 1 回(設定した最小桁)
16 桁の数字 1 回
18 桁の数字 1 回
26 桁の数字 1 回
28 桁の数字 1 回
29 桁の数字 1 回
30 桁の数字 1 回
34 桁の数字 1 回
35 桁の数字 1 回
36 桁の数字 1 回
37 桁の数字 1 回
40 桁の数字 1 回
42 桁の数字 1 回
45 桁の数字 1 回
50 桁の数字 1 回(設定した最大桁)
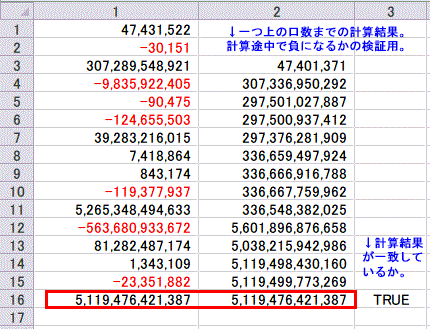
次は、実際の読み上げ算で使われそうな桁数で、かつExcelで簡単に検算できる問題を作ってみましょう。
47,431,522
-30,151
307,289,548,921
-9,835,922,405
-90,475
-124,655,503
39,283,216,015
7,418,864
843,174
-119,377,937
5,265,348,494,633
-563,680,933,672
81,282,487,174
1,343,109
-23,351,882
------------------
5,119,476,421,387
5 桁の数字 2 回(設定した最小桁)
6 桁の数字 1 回
7 桁の数字 2 回
8 桁の数字 2 回
9 桁の数字 2 回
10 桁の数字 1 回
11 桁の数字 2 回
12 桁の数字 2 回
13 桁の数字 1 回(設定した最大桁)
Excelでの検算結果と一致しましたので、大丈夫そうです。
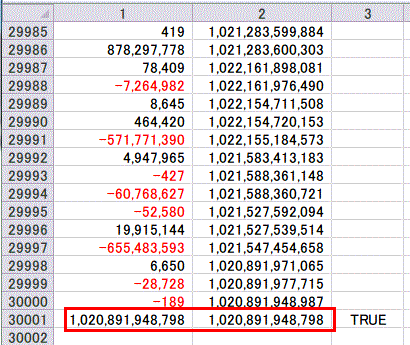
さらにもう一つ、実用性は度外視して、30000口という長い問題で、やはりExcelで簡単に検算できる桁数で作ってみました。
2,186,130
60,457,897
-340,489
-4,222,634
-8,042,129
69,328
-2,986
382,062,921
-324,560
234
(中略)
-571,771,390
4,947,965
-427
-60,768,627
-52,580
19,915,144
-655,483,593
6,650
-28,728
-189
------------------
1,020,891,948,798
3 桁の数字 4286 回(設定した最小桁)
4 桁の数字 4286 回
5 桁の数字 4286 回
6 桁の数字 4285 回
7 桁の数字 4285 回
8 桁の数字 4286 回
9 桁の数字 4286 回(設定した最大桁)
これだけ長い問題になると、さすがに一瞬では終わりません。
……こうしてできた計算部分に、「願いましては」「~円なり」などの読み上げ算用のセリフを加えたものを、system関数で音声読み上げソフトに読ませれば出来上がりです。
読み上げ算:その1
1
7
2
7
-1
9
8
-3
-1
-9
---
20
↑「エラー」「無効なソース」などが表示される場合は、
こちら
をクリックしてみてください。
初心者向けです。
読み上げ算:その2
397,175
64,502
5,037,419,917,233,531
-224,709,834,841,449
57,458,367,135
68,716,726,434,798
8,834,747,857,414
-273,048,150,995
3,532,360
467,625,885
1,697,450,424
33,794,672
-475,931,328,829,828
-29,748
71,598,264,479
----------------------
4,414,188,439,170,355
↑「エラー」「無効なソース」などが表示される場合は、
こちら
をクリックしてみてください。
珠算競技会全国大会の「読み上げ『暗算』」のレベルです。
読み上げ算:その3
93,411,353,616,235,461,093,073,036,055,021,189,852,598,862,104,066,718,878
813,280,150,617,299,232,320,383,821,551,100,635,291,957,698,410,494,184,364,803
-605,611,191,647,069,072,644,181,672,605,623,088,506,184,021,135,922,351,044
2,788,219,776,689,595,194,996,049,870,550,648,841,036,736,162,550,313,336,317
-44,234,082,684,192,748,434,637,557,048,671,585,073,806,707,852,735,042,258,263
--------------------------------------------------------------------------------
771,322,087,871,765,245,469,191,205,736,429,097,160,534,141,561,277,599,810,691
↑「エラー」「無効なソース」などが表示される場合は、
こちら
をクリックしてみてください。
こんなに大きな桁数が入れられるそろばんは、市販品にはないと思います(要特注)。
8132阿僧祇(あそうぎ)
8015恒河沙(こうがしゃ)
0617極(ごく)
2992載(さい)
3232正(せい)
0383澗(かん)
8215溝(こう)
5110穣(じょう)
0635秭(じょ)
2919垓(がい)
5769京(けい)
8410兆
4941億
8436万
4803円なり
となります。
SofTalkに読ませたテキストの2行目は
……その後、試しにOpen JTalkを使うLinux版の方でも同じ問題を読ませてみました。
↑「エラー」「無効なソース」などが表示される場合は、
こちら
をクリックしてみてください。
こちらも、「阿僧祇」の位まできちんと読んでくれていますね。
……さらに、試しにジャストシステムの詠太(8.0.1.0)にも読ませてみたところ、「きゅう、さん、よん、いち……」と、数字の羅列になってしまいました。
とはいえ、詠太は何と言っても有料ソフトですから、当然こちらの方が優れている点もあります。
次の英文は、Marie Louise de la Ramee 作『ウルビーノの子供』の最後の文です。
まずはSofTalk。
↑「エラー」「無効なソース」などが表示される場合は、
こちら
をクリックしてみてください。
……英文のほとんどがアルファベット読みになってしまっていますね。
次は詠太。
↑「エラー」「無効なソース」などが表示される場合は、
こちら
をクリックしてみてください。
……こちらは英文をきちんと英文として読んでくれています。